


据澎湃新闻等报道,英伟达已开发出最新改良版系列芯片——HGXH20、L20PCle和L2PCle。
据行业分析师预计, HGX H20芯片和L20 PCIe GPU预计将于2023年12月推出,而L2 PCIe加速器将于2024年1月推出。
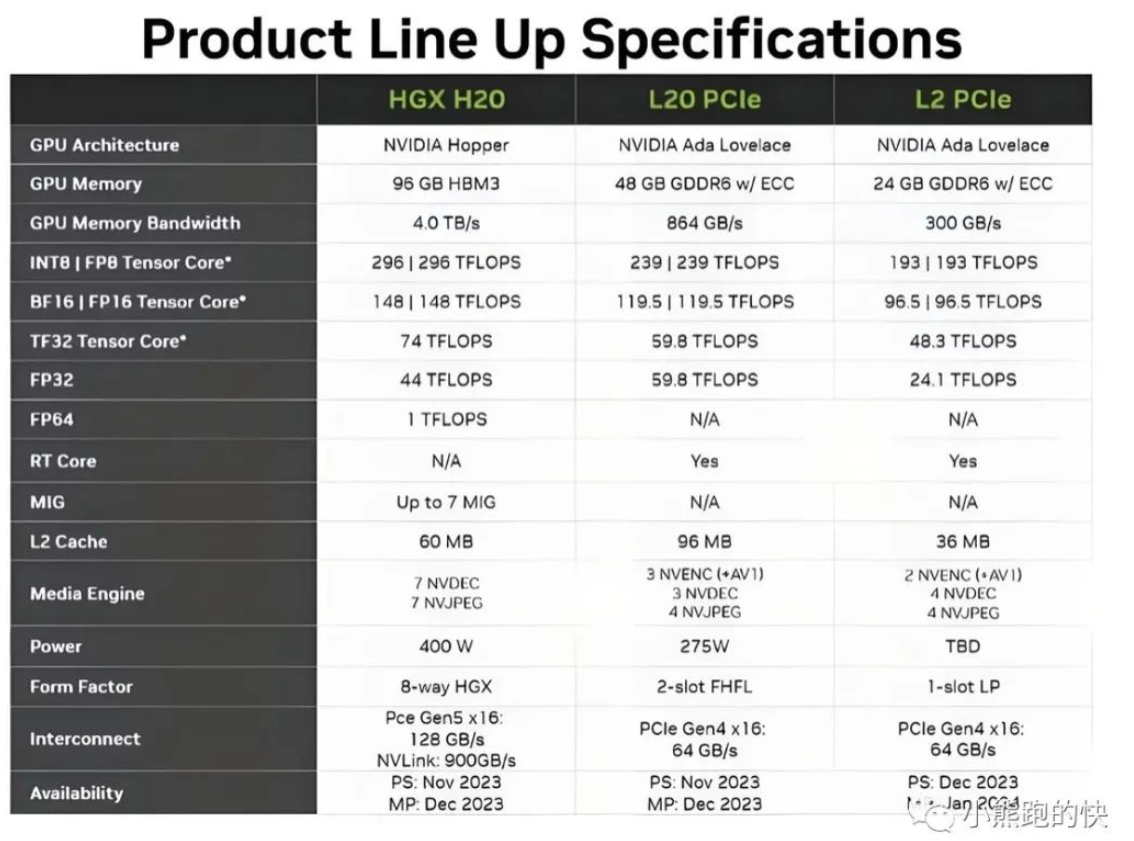
而值得注意的是,虽然算力上与A100有明显差距,但新款算力芯片H20 GPU拥有96GB HBM3内存,内存带宽为4.0 TB/s,这比“全球”H100的3.6 TB/s带宽更高,弥补了算力上的缺陷。
华泰证券表示,AI带动的算力需求快速增长需要存储芯片进行容量与带宽上的配套, GDDR方案带宽迭代速度已难以满足,而带宽更高的HBM方案有望加速增长,预计HBM将在24/25年后成为市场主流。
什么是HBM?
HBM叫高带宽存储器,是AMD和SKHynix联合推出的基于3D堆叠技术的同步动态随机存取存储器(SDRAM),适用于高带宽需求的应用场合,应用于高性能GPU、网络交换及转发设备(如路由器、交换器)、高性能数据中心AI ASIC和FPGA,以及一些超级计算机处理器中。
湘财证券指出,HBM的诞生主要是为了解决“内存墙”和“功耗墙”的问题。
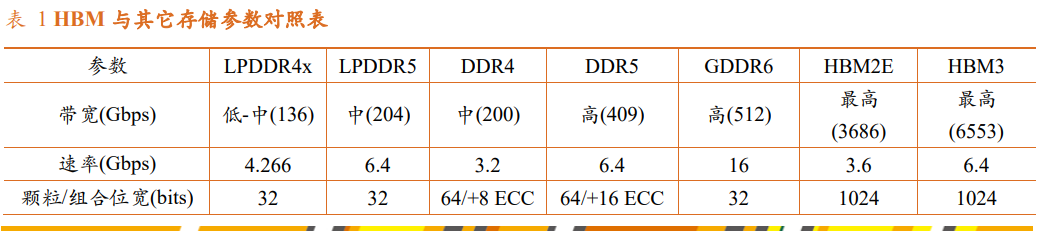

在一些特殊使用场景中(尤其是AI计算领域),处理器经常需要等待内存的数据回传,超高的延时严重拖慢了运算设备整体的运行效率,内存带宽逐渐成为限制计算机发展的关键,HBM通过立体堆叠技术制造完成,这些堆叠的芯片通过称为“中介层(Interposer)”的超快速互联方式,连接至GPU,实现了普通存储8.5倍的带宽,有效解决了内存墙问题
其次,大规模的数据传输需要CPU与存储器通过数据总线进行频繁的数据交换,传输过程消耗的功耗要比计算本身的功耗更大,带来了成本问题,数据中心运营成本中电力成本占到56.70%,而电力成本中67.29%来自于IT负荷,HBM的低功耗优势有利于降低数据中心能源成本。
巨头加码HBM资本开支目前,多家厂商竞相训练大模型,催生了大量需求。
据金融时报的报道,2023年英伟达将出货55万片H100,2024年将出货150-200万片H100,Omdia预测2023年和2024年的HBM需求量将同比增长100%以上。2025年以后,在AI训练需求和AI推理需求的推动下,HBM的需求将继续快速增长,SK海力士公司预测,在2027年之前,HBM市场将以82%的复合增长率保持增长。
在此背景下,三星、美光、海力士三巨头悉数加码HBM的资本开支。
据韩国The Elec报道,三星电子和SK海力士两家公司加速推进12层HBM内存量产。HBM堆叠的层数越多,处理数据的能力就越强,目前主流HBM堆叠8层,而下一代12层也即将开始量产。
另据集邦半导体报道,三星计划在天安厂建立一条新封装线,用于大规模生产HBM,该公司已花费105亿韩元购买上述建筑和设备等,预计追加投资7000亿-1万亿韩元。
美光方面,首席执行官Sanjay Mehrotra稍早前透露,公司HBM3E目前正在进行英伟达认证,计划于2024年初开始大量出货。首批HBM3E采用8-Hi设计,提供24GB容量和超过1.2TB/s频宽。公司计划于2024年推出超大容量36GB 12-Hi HBM3E堆叠。此前美光曾透露,预计2024年新的HBM将带来数亿美元的收入。
国产厂商发力上游材料领域HBM产业链主要由IP、上游材料、晶粒设计制造、晶片制造、封装与测试等五大环节組成,国内厂商则主要处于上游材料领域。
民生证券指出,材料端来看,每个HBM封装内部都堆叠了多层DRAMDie,各层DRAMDie之间以硅通孔(TSV)和微凸块(microbump)连接,最后连接到下层的HBM控制器的逻辑die。因此HBM的独特性主要体现在堆叠与互联上。
对于制造材料,HBM核心之一在于堆叠,HBM3更是实现了12层核心Die的堆叠,多层堆叠对于制造材料尤其是前驱体的用量成倍提升;
对于封装材料,HBM将带动TSV和晶圆级封装需求增长,而且对封装高度、散热性能提出更高要求。
风险提示及免责条款 市场有风险,投资需谨慎。本文不构成个人投资建议,也未考虑到个别用户特殊的投资目标、财务状况或需要。用户应考虑本文中的任何意见、观点或结论是否符合其特定状况。据此投资,责任自负。
